应用情报技术者并不是一个很简单的考试。需要花上一整天时间,上下午连考两场。考试的通过率一直保持在20%出头,论坛上甚至不乏考了七八次还不过的朋友。
但这也不是一个很难的考试。由于可以完全避开编程题,很多非IT岗位的日本人只选经营管理一类的题,考出高分也不罕见。
如果你是完全零基础的上班族的话,至少需要三个月业余时间来学习,也就是说要参加4月的考试,1月开始就必须每天搭上两个小时来做题。做不到这点的话,就只能碰碰运气了。
考试分为午前和午后两部分,每部分两个半个小时。我们先从午前的策略开始谈。。
应用情报
考试对策
午前:考试题都是四选一的单选题,比基本情报稍微难一点。如果没考过基本情报,需要买一本应用情报的教科书,里面会有名词解释和计算技巧之类的知识。可以在刷题前看上一遍。
备考的重中之重,就是刷応用情報技術者試験ドットコム上的过去问。由于考试题大概五成都是从过去问中出的一模一样的原题(不包括最近两次考试),所以只要能将过去十几年的两千道题背个滚瓜烂熟,做到随手能选出八成正确率的话,其他新出的题全蒙也能通过考试。
做题时候,不要按年份,而是按题的分野来做。(图2)最好是看一章书就跟着做一章的题。从题数少,只需要单纯记忆的的マネジメント类开始着手会比较轻松。做完一遍立刻巩固错题,重复个几遍,这个分野你就能切实的拿下。
不会做的题,常错的题,一定要用标记系统标记出来,利用碎片时间反复背答案。(图3)计算题不会的, 果断放弃直接背答案。
做题的后期要做到像巴浦洛夫的狗一样秒选,做到不看题只看选项也能选对。能做到八成正确率,午前就没有不通过的可能。如果算着大概能过的话,能早一个小时交卷最好。因为午休时间极短,到点交卷会没时间吃午饭睡午觉。
总结:闭眼就是做,不会就背过。八成正确率,不过你找我。
午休:午饭尽可能少吃碳水化合物,能趴在桌子上眯一会最好,因为午后考试需要非常集中注意力来阅读文章,可以说是两个半小时的N1节奏加强版。
午后:午后最重要的是选题!(图4)除了必选的1 情報セキュリティ外,还需要在其他十个分野里挑选四个作答。其中2 9 10 11为文系,阅读量大。3 4 5 6 7 8为理系,对计算和相关专业知识有要求。如果有和自己工作相关的分野(比如开发应用程序对应8情報システム開発)的话自然选上比较好,没有的话,就选自己午前正确率高的分野,或者可以从原文里找答案的文系分野比较容易过。11システム監査的考试范围极窄,是选择率最高的一个分野。
选题的话,可以买一本日本人都很推荐的“绿本”(图5),里面会有每个分野的知识说明、历年的出题规律和常见套路分析,附带很详细的说明,比如问答题该如何从原文里按图索骥找到一字不差的答案。事实上,考了几十年的考试很难考出什么花样,做多了你会发现很多题都是老套路(比如令和五年秋的1 情報セキュリティ的电子署名考了绿本的原图)(图6),但做少了就会被“新题型”吓住。午后除了选择题外,还有填空题和几十字的问答题。因此将每一分野十几年的过去问打印出来,然后在纸上边写边做更容易适应考试氛围。如果一开始不会做也没关系,把答案都抄一遍,也就弄明白出题的套路了。
応用情報技術者試験ドットコム的揭示板一定要利用好。比如每次考试结束后的結果報告的帖子里,你会看到大量人的选题心得和书籍推荐。掌握好资讯,就可以大大缩短学习流程。(图7)
此外,练习午前时也要注意背诵该分野选项里的专有名词,因为午后会考这些名词的默写。像是WAF这三个字母的默写,大概就考过四五次。
每年题的难度变化都极不稳定。比如年初考试数据库的难度是最低的1星,年末却可能是最高的10星。但十道大题里每年总归都会有几道奖励考生的送分题。因此多准备几个分野(一般来讲准备五个以上),从中挑选当年简单的比较妥当。从开考前五分钟,发下答题卡的那一刻就要开始选题。有个技巧是可以通过观察答题卡上每个题的选择题数量来预判。比如令和五年秋的数据库没有一道问答题,越看越容易,事实上这也是历史上最简单的一年,几乎是白送20分。如果题一看就无从下手,或者选项里的名词完全不认识的话,就算是最喜欢的分野也要果断放弃。
快速判断题难度的诀窍也是多做过去问。每做完一套题就顺便和其他年份对比一下的话,做个十来套,大概就能准确判断出每一道题目的难易度了。(图8)
考试正式开始的时候,要再花上五分钟来快速浏览试卷判断自己的选题思路,没有问题的话就把选择问题的圈画好开始疯狂答题。考试时间是两个半小时,也就是说30分钟内必须答完一个大题(必考的情報セキュリティ平时要花大力气练,争取20分钟做完,为后面节约时间)。如果有的题实在被卡住不会答就果断放弃(特别是名词填空题),否则后面会答的题没时间答就太遗憾了。到最后五分钟,不会做的一律从原文中随便抄点什么上去,没准就蒙对了。
总结:套路多练习,考过靠选题,每题三十分,千万别着急。
在网络上你可以找到很多人的考试心得。确实有很多名校出身,日语优秀,工作能力强的人裸考也能考出高分。但这种学习方法不适合每个人,不要轻易模仿。
就像跑步一样。短跑极其依赖天赋,能力不行的话就是跑不快。但应用情报技术者更像是长跑,考的是你对题型的熟悉程度而非技术,一次考不过也是对下一次考试的经验积累。只要切切实实的花上训练时间,每个人都能跑下来这20公里的箱根山路。
骐骥一跃,不能十步。驽马十驾,功在不舍。
午前
ライトスルー方式(write through)
CPUから書き込む命令が出たときにキャッシュメモリと同時に主記憶にも書き込む方式。データの整合性は得られるが処理速度は低下する。 →常に主記憶とキャッシュの内容が一致するため一貫性の確保は容易だが、主記憶への書き込みが頻繁に行われるので遅い
ライトバック方式(write back)
CPUから書き込む命令が出たときにキャッシュメモリだけに書き込む方式。主記憶への書き込みはキャッシュメモリからデータが追い出されるときに行われる。 →主記憶とキャッシュの内容が一致しないため一貫性を保つための制御が複雑になるが、主記憶への書き込み回数が少ないため速い

1 クリプトジャッジング ソーシャルエンジニアリング 辞書攻撃 ゼロディ攻撃 XSS フィッシング DNSキャッシュポイズニング ディレクトリトラバーサル ルートキット ビヘイビア WAF ペネトレーションテスト ハイブリッド暗号 エクスプロイトコード SIEM 利用者認証
ディジタルフォレンジックス
6 PRIMARY KEY UNIQUE REFERENCES NOT NULL DEFAULT INSERT INTO VALUES UPDATE SET CREATE VIEW AS () ALTER TABLE DROP COLUMN
8 共通フレーム ファストトラッキング フィット&ギャップ ファクションポイント ウォークスロー インスペクション CMMI リバースエンジニアリング マッシュアップ カプセル化 インテレション ポリモーフィズム トレーサ インスペクタ ペトリネット 負荷テスト パスアラウンド バーンダウンチャート
9 PMBOK WBS RBS クリティカルパス リスク転嫁 「回避」「転嫁」「軽減」「受容」 定量的リスク分析 変更要求 トレンドチャート
10 SLA サービスデスク ローカル 中央 バーチャルサービスデスク フォロー・ザ・サン キャパシティ 目標復旧時点(RPO) 保守性 レプリケーション
11 可監査性 監査証拠 システム監査基準 監査計画の立案 予備調査 本調査 監査証拠 監査報告書の作成 フォローアップ モニタリング 利害関係者 監査調書 突合・照合 インタビュー チェックリスト
イテレーション 継続的インテグレーション
情報セキュリティ
公開鍵暗号方式
流れを確認します。
 1. 前提としてBさんは自分の公開鍵をAさんに配布しておきます。
1. 前提としてBさんは自分の公開鍵をAさんに配布しておきます。
 2. Aさんは送信したいデータをBさんの公開鍵で暗号化し、Bさんへ送信します。
2. Aさんは送信したいデータをBさんの公開鍵で暗号化し、Bさんへ送信します。
 3. Bさんは持っていた自分の秘密鍵を使って受信したデータを復号化して元データを取得します。
3. Bさんは持っていた自分の秘密鍵を使って受信したデータを復号化して元データを取得します。
流れから分かりますが、Bさんは自分の秘密鍵で暗号化されたデータを複合します。ここで複合化できるのはBさんの公開鍵で暗号化されたものです。自分の公開鍵で暗号化されたものは自分の秘密鍵でしか複合化できないので、データを盗聴されても中身までは見られることがなく、安全に受け取ることができます。
一方で、Bさんの公開鍵を配布した人はだれでもデータを暗号化して、Bさんに送ることができるので、なりすましは防ぐことができません。
ディジタル署名
流れを確認します。
 1. 前提としてAさんは自分の公開鍵****をBさんに配布しておきます。
1. 前提としてAさんは自分の公開鍵****をBさんに配布しておきます。
 2. Aさんは送信したいデータをハッシュ化したものと、**自分の秘密鍵で暗号化したもの(ディジタル署名)**をBさんへ送信します。
2. Aさんは送信したいデータをハッシュ化したものと、**自分の秘密鍵で暗号化したもの(ディジタル署名)**をBさんへ送信します。
 3. BさんはAさんの公開鍵を使って受信したデータを復号化し、元データを取得します。
3. BさんはAさんの公開鍵を使って受信したデータを復号化し、元データを取得します。
公開鍵暗号方式の流れと異なる点として、2でAさんは自分の秘密鍵を使って暗号化しています。 3でBさんが、Aさんの公開鍵でデータを複合化して元データ(ハッシュ化されたもの)と一致することを確認します。ここで上記のデータが一致する(Aさんの公開鍵でデータが複合化できる)ということはデータがAさんの秘密鍵で暗号化されたものであることが分かりますが、秘密鍵は本人のみが持っているものなので、Aさんによって送られてきたデータであることが確認できます。
つまり、ディジタル署名を使うことで改ざんやなりすましを検知することができます。
OCSP
(Online Certificate Status Protocol)は、リアルタイムでディジタル証明書の失効情報を検証し、有効性を確認するプロトコルです。OCSPクライアントは、確認対象となるディジタル証明書のシリアル番号等をOCSPレスポンダに送信し、有効性検証の結果を受け取ります。この仕組みを利用することで、クライアント自身がCRL(証明書失効リスト)を取得・検証する手間を省くことができます。
C&Cサーバ
とは、外部から侵入して乗っ取ったコンピュータを利用したサイバー攻撃で、踏み台のコンピュータを制御したり命令を出したりする役割を担うサーバコンピュータのこと。
WAFとは何か
WAF(Web Application Firewall)は、Webアプリケーションの脆弱性を突いた攻撃へ対するセキュリティ対策のひとつです。ネットショッピングやゲーム、インターネットバンキングなど、顧客情報やクレジットカード情報に関するデータのやり取りが発生するWebサービスが保護対象となります。
WAFはWebアプリケーション内に直接実装するものではなく、Webアプリケーションの前面やネットワークに配置し、脆弱性を悪用した攻撃を検出・低減する対策です。WAFの形態によっては、複数のWebアプリケーションに対する攻撃をまとめて防御することもできます。WAFは直接管理・改修することができないWebアプリケーションに対策を施したい場合や、Webアプリケーションの脆弱性を修正することが難しい場合に有効です。あるいは修正に時間が掛かるためすぐに対策を採りたい場合にも役立ちます。
ファイアウォールとの違い
ファイアウォール(Firewall)は、ネットワークレベルでの対策であり、通信において送信元情報と送信先情報(IPアドレス、ポート番号ほか)を元にして、アクセスを制限するソフトウェアおよびハードウェアのことを指します。ファイアウォールは外部へ公開する必要がなく、社内でのみ使用する情報システムへの外部からのアクセスを制限することは可能です。
しかし、外部へ公開する必要のあるWebアプリケーションに制限を掛けることはできません。外部へ公開するWebアプリケーションのセキュリティ対策は、ファイアウォールではなくWAFの範疇となります。
IPS/IDSとの違い
IPS(Intrusion Prevention System)は不正侵入防止システムとも呼ばれる、プラットフォームレベルでのセキュリティ対策を行うソフトウェア・ハードウェアを指します。
OSやミドルウェアの脆弱性につけ込んで攻撃を行うケースや、ファイル共有サービスへの攻撃を行うケースなど、さまざまな種類の攻撃への対策が可能です。Webサイトの管理者などによって設定された検出パターンに基づき、あらゆる種類の機器への通信を検査しブロックします。
IDS(Intrusion Detection System)は不正侵入検知システムとも呼ばれ、異常な通信を検知するものです。IPS/IDSはさまざまな攻撃への対策手段となり得ますが、Webアプリケーションへの攻撃は多様化しているため、WAFほど詳細に検知できない場合もあります。
攻撃
DNSキャッシュポイズニング
は、DNSキャッシュサーバに偽のDNS情報をキャッシュとして登録させることで、利用者を偽のWebサイトに誘導する攻撃です。
ペネトレーションテスト
(Penetration Test)は、ネットワークに接続されているシステムに対して、実際に様々な方法で侵入や攻撃を試みることで脆弱性の有無を検査するテストです。侵入テストとも呼ばれます。
ビヘイビア法
は、ウイルスの実際の感染・発病動作を監視して検出する手法です。 感染・発病動作として「書込み動作」「複製動作」「破壊動作」等の動作そのものの異常を検知するだけでなく、感染・発病動作によって起こる環境の様々な変化を察知してウイルスを見い出すこともあります。例えば「例外ポート通信・不完パケット・通信量の異常増加・エラー量の異常増加」「送信時データと受信時データの量的変化・質的変化」等がそれに該当します。
ペネトレーションテスト
は、ネットワークに接続されているシステムに対して、実際に様々な方法で侵入や攻撃を試みることで脆弱性の有無を検査するテストです。
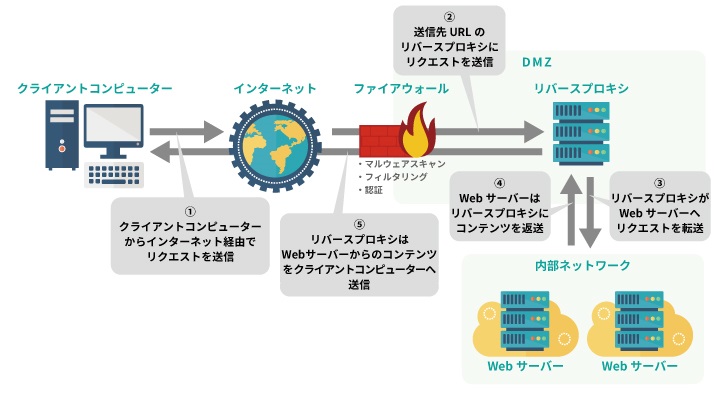
リバースプロキシ
は、外部インターネットからサーバーへアクセスされる通信を中継する仕組みを指す。前述のプロキシ(フォワードプロキシ)と比較すると、インターネットへ接続する方向が逆(リバース)になるため、リバースプロキシと呼ばれる。
負荷分散や高速化の機能を提供するリバースプロキシ
https://eset-info.canon-its.jp/files/user/malware_info/images/special/201021/2.jpg
{kind=link}
请求百度,背后有无数台服务器,不知道请求的是哪一台
SSL
(Secure Sockets Layer)は、インターネット上のウェブブラウザとウェブサーバ間でのデータの通信を暗号化し、送受信させる仕組み(プロトコル)です。個人情報やクレジットカード情報などの重要なデータを暗号化して、サーバ~PC間での通信を安全に行なうことができます。
SSLは、主にウェブサイトから情報を送信する際に、情報を暗号化する為に利用をします。サイトの管理者は、送信される情報を悪意を持った第三者から守ると同時に、送信される情報が改ざんをされていないことを証明することができます。つまり、ウェブサイトを運用する上でSSLは切っても切れない関係です。
SSL暗号化通信が行われていない場合は、データが平文のままのため、盗聴や改ざんを防げません。この場合、URLの先頭は『http://』となり、注意や警告マークが表示されます。
ユーザにより安心してウェブサイトを利用してもらうには、SSL暗号化通信に必要な鍵と、ウェブサイトの運営者の情報が含まれた「SSLサーバ証明書」をウェブサーバにインストールする必要があります。
SSLサーバ証明書は、ウェブサイトの「運営者の実在性を確認」し、ブラウザとウェブサーバ間で「通信データの暗号化」を行うための電子証明書で、GMOグローバルサインなどの認証局から発行されます。
なりすまし

ウェブサイトの運営者になりすました第三者が、ログイン情報や決済情報などを取得し不正に取引を行うこと。
盗聴
インターネット上で送受信される個人情報や決済情報、Cookieなどの機密性の高いデータを第三者が盗み見する行為のこと。
改ざん
悪意ある第三者が、ユーザがフォームから送った内容を通信の途中で書き換えること。
データベース
ER図



正規形

【第1正規形】繰り返しを整理
データベースでは、レコード単位でデータを扱うため、正規化前のようなデータはデータベースに格納することすらできません。
まずは、繰り返し項目のそれぞれを別レコードとして独立させ、各レコードの長さを整えます。(正規化前は、各レコードの長さがバラバラで商品が繰り返されている状態)

上記が「第1正規形」の表(テーブル)です。背景色がついている行(レコード)が、正規化前では繰り返し項目になっていた部分です。
繰り返し項目を別レコードとして独立させることで、すべてのデータをデータベースに格納することができました。
【第2正規形】部分関数従属している列を整理
第2正規形では、部分関数従属している列を整理します。
「部分関数従属」って何ですか?
まずは「部分関数従属」について説明します。
例えば、第1正規形で作られた表(テーブル)の主キーは「注文番号」と「商品ID」です。
「注文番号」と「商品ID」が決まれば、行(レコード)を一意に特定することができますが、実は「注文番号」が決まるだけで「注文日」「ユーザID」「購入ユーザ名」は特定することができます。このような関数が部分関数従属です。
そして、第1正規形の表(テーブル)から、部分関数従属している列(レコード)を切り出したものが「第2正規形」です。
次の表(テーブル)は部分関数従属のイメージ例です。

オレンジ枠の部分は「注文番号」が決まれば特定できる項目、緑枠の部分は「商品ID」が決まれば特定できる項目です。
下記が「第2正規形」の表(テーブル)です。

オレンジ枠で囲んだ部分を「注文テーブル」、緑枠で囲んだ部分を「商品テーブル」として切り出しています。そして残った部分を「注文詳細テーブル」として3つの表(テーブル)に分けています。
【第3正規形】関数従属している列を整理
第3正規形では、主キー以外の列に関数従属している列を整理します。関数従属とは「○○が決まれば特定できる項目」のことです。
第2正規形の「注文テーブル」は「注文番号」が主キーです。そのため「注文番号」が決まれば行(レコード)を一意に特定することができます。
しかし、よく見ると「注文番号」以外の列に関数従属している項目があります。それは「購入ユーザ名」です。「購入ユーザ名」は、「ユーザID」が決まれば特定できる項目です。
次の表(テーブル)は関数従属のイメージ例です。

緑枠の部分は主キー以外である「ユーザID」が決まれば特定できる項目です。このように、第3正規形では、主キー以外の列に関数従属している列を整理します。
下記が「第3正規形」の表(テーブル)です。

緑枠で囲んだ部分を「ユーザテーブル」として切り出しています。
正規化で不具合発生しないの理由、いちも変更されないからです
ビュー
(View)は1つ以上のテーブルから必要な要素のみを取得して作成される仮想的なテーブルのようなもの。
– ビューの定義
CREATE VIEW MathPointList
AS SELECT ID, Name, Class, Math FROM PointList;
CREATE VIEW MathPointList (ID,Name,Class,数学)
AS SELECT ID, Name, Class, Math FROM PointList;
ビューの定義を変更したい場合には、「ALTER VIEW文」と「CREATE VIEW OR REPLACE文」が利用可能でしたね。
- ALTER VIEW office_view AS
- select office.office_name, region.region_name
- from office
- inner join region
- on region.id = office.region_id;
集計関数
- SUM: 合計を計算
- AVG: 平均を計算
- COUNT: レコード数を計算
- MAX: 最大値を計算
- MIN: 最小値を計算
select句で指定する項目(※1)は、gourp byの項目として指定している必要があります。 →group byに項目があり、select句の後に項目がない場合は実行できます。
GROUP BY
select [表示する要素名] from [テーブル名] GROUP BY [グループ化する要素名];
例えば、商品名ごとの合計、平均、最小値、最大値などをすることです。 SQLでのグルーピングは、 GROUP BYを使います。 GROUP BYもORDER BYもWHEREなどと同様に、SELECT文に付けることで、グルーピングすることが可能です。
GROUP BY句を使用することで、同じ値同士のデータをグループ化、そして集合関数を使いグループごとに集計することができます。
|
|
集約関数の値に条件を指定する(having)
select 項目 from テーブル名 group by 項目 having 条件
WITH句
を使えば1つの副問い合わせ(SQL)を複数の箇所で使いまわすことができます。
例としてSQL 副問い合わせの基本を理解するで扱ったFROM句の副問い合わせのSQLをおさらいします。
もしこのSQLで「2015年5月の売上のみ集計したい」という場合、副問い合わせを使えば、下記のSQLのようになります。
|
|
この方法では、T2,T3を取得する副問い合わせのSQLでそれぞれ売上明細テーブルを同じように集計しています。
そのため、売上明細テーブルに大量のデータがあった場合、レスポンスがどんどん遅くなってしまいます。
WITH句で同じような集計テーブルは最初に指定してしまいます。
WITH句を指定したSQLは下記のようになります。
|
|
ALTER TABLE
|
|
GRANT文
は、特定のユーザに表などのデータベースオブジェクトに対する権限を付与するSQL文です
GRANT オブジェクトの権限 ON オブジェクト名 TO { ユーザ名 | ロール名 | PUBLIC } [ WITH GRANT OPTION ]
反対に付与されている権限を取り消すには、REVOKE文を使用します。
REVOKE オブジェクトの権限 ON オブジェクト名 FROM { ユーザ名 | ロール名 | PUBLIC }
射影
は、関係演算の1つで関係(表)の中から特定の属性(列)の集合を取り出す操作です。

選択
表から指定された行(タプル)を抽出する操作

2相コミットプロトコル
は、トランザクションを他のサイトに更新可能かどうかを確認する第1相と、更新を確定する第2相の2つのフェーズに分け、各サイトのトランザクションをコミットもロールバックも可能な中間状態(セキュア状態)にした後、全サイトがコミットできる場合だけトランザクションをコミットするという方法で分散データベース環境でのトランザクションの原子性・一貫性を保証する手法です。
具体的には、各サイトの更新処理が終わった後に、コミットの調整を行う1つのノードを「主サイト」、ネットワーク上の他のノードを「従サイト」として、次の手順でコミットが行われます。
[第1相(投票層)]
- 調停者となったノードはネットワーク上の他のノードにコミットの可否を問い合わせる。
- 全参加者は調停者にコミットの可否を応答する。
[第2相(決定相)]
- 全参加者からコミットの合意を得られた場合は、全参加者にコミットの実行要求を発行する。コミットの停止を応答した参加者がいた場合、またはタイムアウトとなった場合は、全参加者にロールバックの実行要求を発行する。
- 各参加者は、コミット(またはロールバック)の完了とともに調停者に処理完了のメッセージを送る。
- 調停者が、全参加者からの処理完了メッセージを受け取り、トランザクションの完了となる。

3層スキーマ
概念スキーマ
データベース化対象の業務とデータの内容を論理的なデータモデルとして表現したもの。概念スキーマを記述するために記号系にはリレーショナルモデルの他にも、ネットワークモデル、階層型モデルなどがある。リレーショナルモデルではE-R図の作成、表定義、表の正規化が概念スキーマに相当する。
外部スキーマ
概念スキーマで定義されたデータモデル上に利用者ごとの目的に応じた見方を表現したもの。リレーショナルモデルのビューやネットワークモデルのサブスキーマが外部スキーマに相当する。
内部スキーマ
概念スキーマで定義されたデータモデルを記憶装置上にどのような形式で格納するかを表現したもの。ファイル編成やインデックスの設定などが内部スキーマに相当する。

ACID 特性:原子性、一貫性、独立性、永続性
ACID とは、トランザクションを定義する4つの重要な特性、**Atomicity(原子性)、Consistency(一貫性)、Isolation(独立性)、****Durability(永続性)**の頭文字をとった略語です。データベース操作にこれらの ACID 特性がある場合は、ACID トランザクションと呼ぶことができます。また、これらの操作を適用したデータストレージシステムは、トランザクションシステムと呼ばれます。ACID トランザクションにより、テーブルの読み取り、書き込み、変更の各処理で次の特性が保証されます。
- **原子性(A):**トランザクションの各ステートメント(データの読み取り、書き込み、更新、削除)は、1 つの単位として扱われます。ステートメントは、実行されるか、あるいは全く実行されないかのいずれかです。この特性は、ストリーミングデータソースがストリーミングの途中で障害が発生した場合などに、データの損失や破損が発生するのを防ぎます。
- **一貫性(C):**トランザクションがテーブルに、事前定義された予測可能な方法でのみ変更を加えることを保証します。トランザクションの一貫性により、データの破損やエラーが起きた場合でもテーブルの整合性を保ち、意図しない実行結果を防ぎます。
- **独立性(I):**複数のユーザーが同じテーブルで読み書きを同時に実行しても、トランザクションが分離され、同時進行のトランザクションが相互に干渉したり、影響を受けたりしないようにします。実際は、同時に発生していも、各要求は単独で発生しているように扱われます。
- **永続性(D):**システム障害が発生した場合でも、正常に実行されたトランザクションによるデータの変更が保存されることを保証します。
情報システム開発
ホワイトボックステストの網羅基準
ホワイトボックステストには「命令網羅」「判定条件網羅」「条件網羅」「複数条件網羅」と呼ばれる網羅基準が存在します。
スポンサーリンク
命令網羅
命令網羅とは、すべての処理(命令)を最低1回は通すようにする試験です。すべての処理を網羅できる入力データを準備して、内部処理が正しく動作することを確認します。

例えば、上記のような内部処理で命令網羅するためには、「A=真、B=真」の入力データが必要です。
[テストデータ]
| 試験パターン | 入力値「A」 | 入力値「B」 |
|---|---|---|
| 1 | 真 | 真 |
判定条件網羅(分岐網羅)
判定条件網羅(分岐網羅)とは、すべての分岐を最低1回は通す試験です。すべての分岐を網羅できる入力データを準備して、内部処理が正しく動作することを確認します。

例えば、上記のような内部処理で判定条件網羅するためには、「A=真、B=真」と「A=真、B=偽」または「A=偽、B=真」または「A=偽、B=偽」の入力データが必要です。
[テストデータ]
| 試験パターン | 入力値「A」 | 入力値「B」 |
|---|---|---|
| 1 | 真 | 真 |
| 2 | 真 | 偽 |
※試験パターン2は、逆でも両方「偽」でもよい。
条件網羅
条件網羅は、個々の条件を最低1回は満たすようにする試験です。例えば、次のような内部処理では、AとBには「真」と「偽」の値が入る可能性があります。この個々(今回の例ではAとB)の条件(真 or 偽)をそれぞれ1度ずつ試すのが条件網羅です。

上記のような内部処理で条件網羅するためには、「A=真、B=真」と「A=偽、B=偽」の入力データ もしくは 「A=真、B=偽」と「A=偽、B=真」もしくは「A=偽、B=真」と「A=真、B=偽」の入力データが必要です。
[テストデータ 例1]
| 試験パターン | 入力値「A」 | 入力値「B」 |
|---|---|---|
| 1 | 真 | 真 |
| 2 | 偽 | 偽 |
または
[テストデータ 例2]
| 試験パターン | 入力値「A」 | 入力値「B」 |
|---|---|---|
| 1 | 真 | 偽 |
| 2 | 偽 | 真 |
または
[テストデータ 例3]
| 試験パターン | 入力値「A」 | 入力値「B」 |
|---|---|---|
| 1 | 偽 | 真 |
| 2 | 真 | 偽 |

AとBで1度ずつ「真」と「偽」が試せればよいので、例1、例2、例3どのテストデータを使っても条件網羅の目的は達成できます。
複数条件網羅
複数条件網羅は、想定される条件の組み合わせをすべて網羅する試験です。例えば、次のような内部処理では、AとBには「真」と「偽」の値が入る可能性があります。このAとBの条件の組み合わせをすべて網羅するのが複数条件網羅です。
上記のような内部処理で複数条件網羅するためには、「A=真、B=真」「A=真、B=偽」「A=偽、B=真」「A=偽、B=偽」の入力データが必要です。
[テストデータ]
| 試験パターン | 入力値「A」 | 入力値「B」 |
|---|---|---|
| 1 | 真 | 真 |
| 2 | 真 | 偽 |
| 3 | 偽 | 真 |
| 4 | 偽 | 偽 |
コンポジション
PCは本体、ディスプレイとキーボードから成ります。xx社製xxモデルというデスクトップPCを購入すると、これらの3つの部品で1つのセットになっています。これら3つの部品はそれぞれ独立してほかのPCに流用することができます。本体が壊れてもディスプレイを取り外して使用できます。
ノートPCは本体、ディスプレイとキーボードが一体構造となっていて、このようなことはできません。本体が壊れたからといってディスプレイを取り外して使用することは通常できません。このような強い集約関係がコンポジションです(図13)。

プロジェクトマネジメント
フィット&ギャップ分析(Fit&Gap分析)
**とは、「自社の要件」と「パッケージやSaaS等の機能」を比較し、**パッケージやSaaS等が自社の要件をどの程度網羅しているのかを確認する取り組みのこと。
フィット&ギャップ分析は一般的にパッケージやSaaSを選定する際に用いる手法です。自社の要件を縦軸に、各製品を横軸に並べ、製品ごとにどの要件をカバーできているか、もしくはできていないかを星取表で整理します。そして、製品ごとに自社の要件と機能との適合率を算出します。例えば、自社の要件が100あったとして、うち80の要件を実現できる製品であれば、適合率は80%となります。
具体的には、下表のようなイメージとなります。
| 自社要件 | 製品A | 製品B | 製品C | 製品D | ・・・ |
|---|---|---|---|---|---|
| ログイン機能 | 〇 | 〇 | △ ※パスワードリセット機能なし | 〇 | ・・・ |
| 営業状況登録機能 | 〇 ※Salesforceとの連携可能 | 〇 | 〇 | 〇 | ・・・ |
| 見込み顧客管理機能 | 〇 | 〇 | 〇 | 〇 | ・・・ |
| ステップメール管理機能 | × | 〇 ※開封率を考慮して送付内容を変更可能 | 〇 | 〇 | ・・・ |
| SNSマーケ機能 | 〇 | × | × | × | ・・・ |
| ・・・ | ・・・ | ・・・ | ・・・ | ・・・ | 66% |
| 適合率 | 66% | 75% | 80% | 61% | 66% |
マイナスのリスクへの対応策
PMBOK第5版によれば、には以下の4つがあります。
-
回避
リスクを完全に取り除く戦略です。情報漏洩リスクに対して、そもそも情報を持たないこと等が当てはまります。
-
軽減
リスク発生の確率や発生した場合の影響度を下げる戦略です。自動車事故に対して、速度を落とすことなどが当てはまります。
-
転嫁
リスクが避けられない場合、リスク発生時の責任を他者に渡す戦略です。自動車事故に対する自動車保険などが当てはまります。
-
受容
リスク発生の可能性が低く影響度も低い場合、あえて対策を行わず、リスクが発生した場合は受け入れることを容認する戦略です。
リスク特定で使われるツールと技法
-
インタビュー
類似プロジェクトの経験者、ステークホルダ、専門家との直接会話によってプロジェクトに必要な情報を得る手法
-
根本原因分析
リスクを引き起こす根本原因を特定するために用いられる分析手法
-
前提条件分析
プロジェクトの前提条件の不正確さ、不安定さ、不整合さ、ならびに不完全さを分析することでリスクを特定する
-
専門家の判断
類似プロジェクトや事業分野に経験を持つ専門家がリスクを直接特定する方法
-
チェックリスト分析
過去の類似プロジェクトその他の情報源で蓄積した情報や知識から作成したリスクの一覧表を用いてリスクの特定を行う技法
-
デルファイ法
プロジェクトリスクについての複数人の専門家から匿名でアンケートを行い、その結果を要約したものを再び専門家に配布することを繰り返して合意を形成し、リスクの特定を行う方法
-
ブレーンストーミング
批判の禁止・自由奔放・質より量・結合/便乗歓迎というルールに則って行われるグループ討議で、広範なリスク一覧表を作成するための意見を多く集めるために実施される
サービスマネジメント
SLA
IT サービスの提供に当たって IT サービスを提供する側と利用者との間でサービスの品質(サービスレベル)に関する合意(SLA : Service Level Agreement)を取り交わし,システムの稼働状況や対応状況を監視,記録を行い,サービス品質を維持する。
SLA には,システムの稼働時間や問合せの受付時間帯,障害発生時の回復時間,システムの性能などのサービスレベルの水準と,サービスレベルを下回った場合の罰則事項などを規定している。
次の条件で IT サービスを提供している。SLA を満たすことができる,1 か月のサービス時間帯中の停止時間は最大何時間か。ここで,1 か月の営業日数は 30 日とし,サービス時間帯中は,保守などのサービス計画停止は行わないものとする。
SLA の条件
- サービス時間帯は,営業日の午前 8 時から午後 10 時までとする。
- 可用性を 99.5 % 以上とする。
(出典)平成30年度 秋季 基本情報技術者試験 午前問題 問57
1 か月のサービス時間帯中の停止時間の最大値は次式で求められる。
14 [時間/日] × 30 [日] × (1 - 0.995) = 2.1 [時間]
SLA
IT サービスの提供に当たって IT サービスを提供する側と利用者との間でサービスの品質(サービスレベル)に関する合意
サービス可用性
あらかじめ合意された時点又は期間にわたって,要求された機能を実行するサービス又はサービスコンポーネントの能力
信頼性
サービス時間
応答時間
インシデント管理
① インシデントの対応
-
インシデント管理
インシデントが起こったときに,できる限り迅速に通常の状態に再開させるためのプロセス
-
インシデント
運用上で起きたシステム上の障害となる脅威の事象のこと。
エスカレーション(機能的エスカレーション,階層的エスカレーション)
サービス及びサービスマネジメントシステムのパフォーマンス
表 サービスライフサイクルの段階
| サービス戦略 | IT サービスの指針を定義する段階 |
|---|---|
| サービス設計 | 適切な IT サービスを設計及び開発する段階 |
| サービス移行 | サービスの実現を計画立案及び管理する段階 |
| サービス運用 | サービスの提供とサポートに必要な活動をする段階 |
| 継続的サービス改善 | IT サービスの有効性と効率性を継続的に改善する段階 |
サービスデスクの組織構造
-
ローカルサービスデスク
ユーザのローカルサイト内、若しくは地理的に近い場所に設置されたサービスデスク。担当者の直接派遣が容易であり、ユーザの問題や改善点を把握しやすい。
-
中央サービスデスク
一箇所の拠点にてすべてのユーザからの問い合わせに対応する体制のサービスデスク。運営コストを低く抑えることができ情報の管理がしやすい。
-
バーチャルサービスデスク
実際には分散しているが連携することで擬似的に一つの組織として機能を提供するサービスデスク。
-
フォロー・ザ・サン
2つ以上の異なる(大陸の)拠点に配置され、中央での統括管理によって24時間365日のサービスを提供するサービスデスク。
問題管理プロセス
インシデントの根本原因を特定し、インシデント及び問題の影響を最小化又は回避することを目的とするプロセスです。主な活動は以下の通りです。
- インシデントの根本原因と潜在的な予防処置を特定する
- 問題解決のための変更要求を提起する
- サービスへの影響を低減又は除去するための処置を特定する
- 既知の誤りを記録する
システム監査
予防的コントロールの観点からの改善勧告と,発見的コントロールの観点からの改善勧告を,それぞれ30字以内で具体的に述べよ。
|
|
なお、この「作業後のチェックがないために不適切(あるいは改善した)」という出題のされ方は、応用情報技術者試験の午後試験で頻出されています。午後試験でプロジェクトマネージャ(問9)やシステム監査(問11)の分野を選択する予定の方は覚えておいた方が良いでしょう。
システム監査はちょっとしたノウハウがあって、覚えておくことは「職務の分離」「最少権限の原則」「監査時の7つの技法」です。
職務の分離
とは、業務の担当者と承認者を分離するなど、職責と権限を適切に分配することでそれぞれの担当者間で相互牽制が働く仕組みを作ることをといいます。内部統制では、業務の適正さを保つ組織体制を築き維持していくことが求められるので、職務の分離は内部統制システムを有効に機能させるために有効な要素と言えます。
最小権限の原則
とは「任命された業務を遂行するために必要な最小限のアクセス権のみを与えること」を指す。これを徹底することで,不正な行為を予防し,外部からの侵入などの場合にも,その被害の範囲や損害を最小限にできる。特に,論理アクセス,物理アクセスでは,この「最小権限の原則」とともに「職務の分離」(Segregation of Dutiesと呼ばれる場合もある)を行うことで,単独行動としての不正行為の成立を難しくし,他の人間と共謀しなければ不正行為ができなくなる。
監査技法
システム監査基準(平成30年)における監査手続の実施に際して利用する技法
インタビュー法とは,システム監査人が,直接,関係者に口頭で問い合わせ,回答を入手する技法をいう。
現地調査法とは、システム監査人が、被監査部門等に直接赴き、対象業務の流れ等の状況を、自ら観察・調査する技法です。
コンピュータ支援監査技法とは、監査対象ファイルの検索、抽出、計算等、システム監査上使用頻度の高い機能に特化した、しかも非常に簡単な操作で利用できるシステム監査を支援する専用のソフトウェアや表計算ソフトウェア等を利用してシステム監査を実施する技法です。
チェックリスト法とは、システム監査人が、あらかじめ監査対象に応じて調整して作成したチェックリスト(通例、チェックリスト形式の質問書)に対して、関係者から回答を求める技法です。
システム監査基準(平成30年、2018年)
http://www.kogures.com/hitoshi/webtext/std-system-kansa/index.html
【合否】 合格 【午前点数/午後点数】 午前 66.25 / 午後 71 【午後自己採点との差】 あり(TAC+1, iTEC+4) 【今回が何回目の受験か?】 1回目 【午後選択問題】 1 情報セキュリティ 4 システムアーキテクチャ 6 データベース 8 情報システム開発 11 システム監査 【どれぐらい勉強した?】80時間くらい 【勉強方法】 午前:過去問道場 直近除く過去問5年分繰り返す 午後:緑本を繰り返す+パーフェクトラーニング繰り返す 【ひとこと】 春に基本情報に合格した勢いで今回の受験、合格となりました。私はIT業界で勤めており、本番では実務での経験に助けられもしましたが、それなりに勉強は必要でした。午前はこちらの過去問道場一本で対策し、最終的には三段になるまで過去問を繰り返しました。それでも午前66点と、それほど立派な点数ではありませんでしたが。。。今回は自分向きの午後問題をうまく選択できたので合格できたと思っています。
【合否】 合格 【午前点数/午後点数】 午前 71 / 午後 64 【午後自己採点との差】 やってない 【今回が何回目の受験か?】 1回目 【午後選択問題】 1 情報セキュリティ※必須 2 経営戦略 6 データベース 9 プロジェクトマネジメント 11 システム監査 【どれぐらい勉強した?】4カ月、しっかり計測してない ・平日:週2くらいで3時間くらい ・休日:~6時間 【勉強方法】 このサイトでひたすら過去問を解く 他の教本はほぼ使ってないです。 【ひとこと】 基本情報に引き続きこちらのサイトには大変お世話になりました!高度情報受けるかはもう少し考えます…笑
書き残しておきます。 【合否】 合格 【午前点数/午後点数】 午前 67 / 午後 65 →多分下駄だなあと思いました。公式解答と自分の解答が全く違ったので。 もしくは部分点とかがあったのかな? 【午後自己採点との差】 あり(-11点) →甘めの採点だったので納得です。 【今回が何回目の受験か?】 1回目 【午後選択問題】 1 情報セキュリティ※必須 2 組み込みシステム開発 3 情報システム開発 4 サービスマネジメント 5 システム監査 →本来はシステムアーキテクチャを選択するつもりでしたが、見るからに難しそうだったので急遽情報システム開発にチェンジ。結果自己採点だと12点でした。 【どれぐらい勉強した?】2カ月 →高校生なので夏休みを利用して勉強しました。 【勉強方法】 過去問道場を利用しました。基本情報の知識があったので、地力がある方は過去問道場のみでも全然問題ないと思います。 【ひとこと】 組込みシステム開発が無かったら絶対に不合格だったので、ラッキーでした。試験の帰り道でも雨が降っており、傘に二度助けられた感じですね。 次は情報処理安全確保支援士を受けます。